软件所提出一种基于启发式解耦视角的自监督视频表示学习方法
近日,软件所天基综合信息系统全国重点实验室研究团队聚焦自监督视频表示学习中静态与动态语义难以兼顾的问题,提出一种基于启发式解耦视角的双层优化方法。相关成果论文Self-Supervised Video Representation Learning in a Heuristic Decoupled Perspective在计算机视觉与人工智能领域顶级期刊 International Journal of Computer Vision (IJCV) 上发表。论文第一作者为博士生宋泽恩,通讯作者为副研究员强文文。
自监督视频表示学习无需依赖人工标注数据,即可从视频中学习通用特征,在动作分类、时序动作检测等任务中得到广泛应用。然而,现有方法在训练过程中容易过度依赖背景等静态特征,而忽视运动等动态特征,这种现象被称为“静态偏差”或“捷径学习”。传统对比学习方法通常采用统一的相似度度量,难以区分静态与动态语义学习难度的差异。在动态信息主导的复杂场景下,动态语义的学习易被抑制,从而影响视频模型在细粒度动作识别等任务中的表现。
针对上述问题,研究团队首先构建了一个结构因果模型,用以分析视频样本作为混淆变量如何导致静态与动态语义之间产生虚假关联,并从理论上证明在统一损失函数下,梯度更新会偏向于容易学习的语义分量,导致动态语义被抑制。研究团队进而提出了一种面向视频语义解耦的自监督学习方法BOD-VCL。该方法包括三个关键模块:一是Koopman算子估计模块,利用神经网络拟合Koopman算子,将非线性视频帧演化映射到线性空间,为语义解耦提供动力学分析基础;二是启发式语义解耦模块,基于特征值分解规则,将特征空间划分为静态子空间和动态子空间;三是双层优化解耦学习模块,通过内层优化算子预测性能、外层优化解耦对比损失的迭代策略,减少静态与动态特征间的梯度干扰,确保两类语义均得到有效优化。
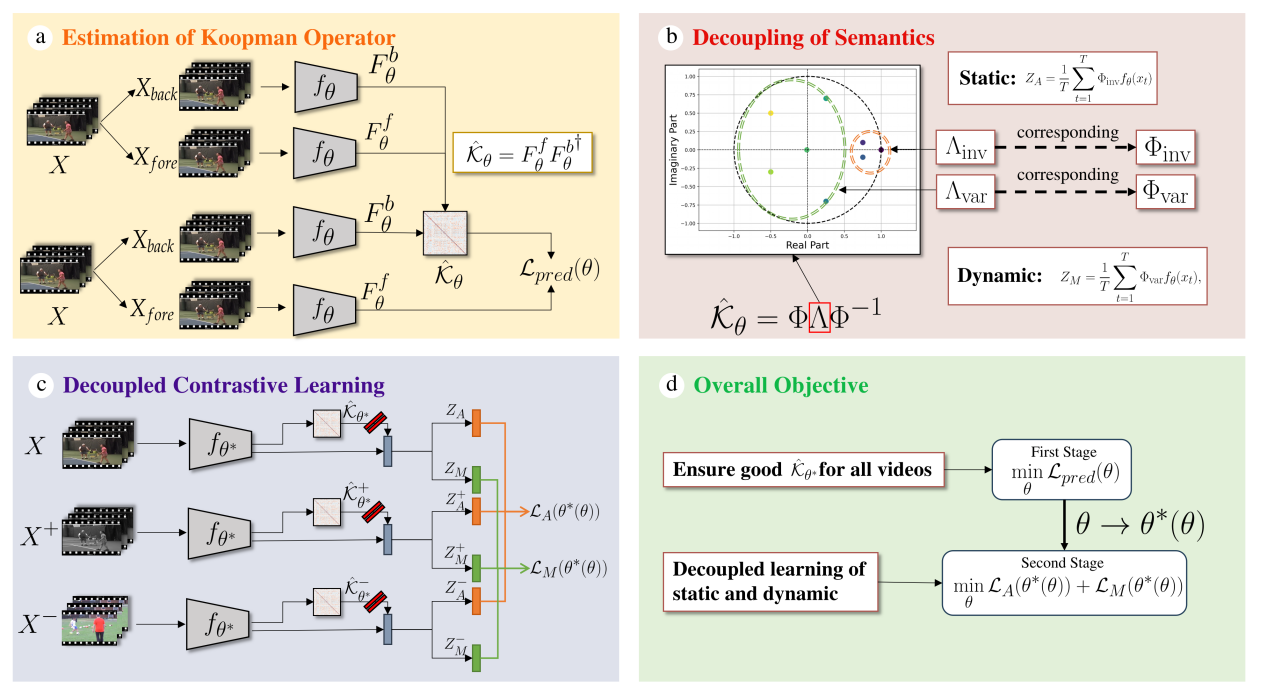
算法框架图
研究团队在多个视频理解基准数据集上对方法进行了评估,包括Kinetics-400、UCF-101、HMDB-51,以及运动语义占主导的Something-Something v2(SSv2)和FineGym等数据集。实验结果表明,该方法均取得优于基线模型的性能表现。特别是在SSv2数据集上,BOD-VCL显著超越了原始基线模型,表明其在捕捉动态语义方面的优越性。合成数据集上的消融实验进一步验证了双层优化机制在缓解梯度干扰方面的作用。此外,BOD-VCL具有高度通用性,可灵活适配V-BYOL、V-MoCo等主流框架。
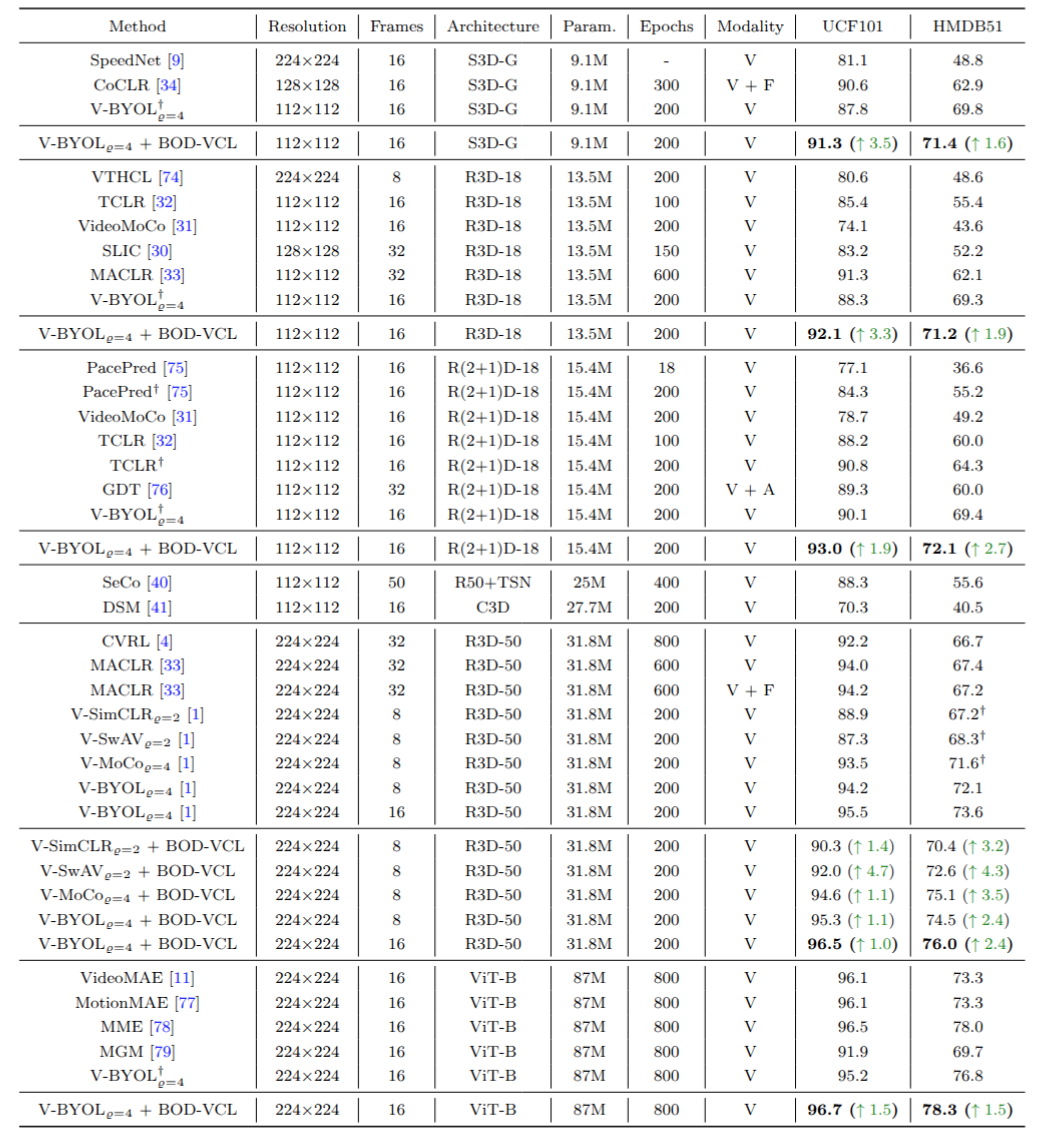
在动作识别任务上的性能评估

基于GradCAM的可视化结果
论文链接:https://arxiv.org/abs/2407.14069