
天基综合信息系统全国重点实验室入选CVPR 2026论文概览
文章来源: | 发布时间:2026-04-23 | 【打印】 【关闭】
近日,软件所天基综合信息系统全国重点实验室多篇论文被计算机视觉与模式识别会议The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026(CVPR 2026)录用。以下是成果介绍,欢迎大家交流讨论。
1. Multi-modal Test-time adaptation via Adaptive Probabilistic Gaussian Calibration
作者:徐菁琳、李懿、孙楚雄、许霄、李江梦、徐帆江
多模态测试时自适应(Multi-modal Test-Time Adaptation, TTA)旨在推理阶段利用无标注的目标域数据,提升预训练多模态模型在分布偏移情况下的鲁棒性。尽管多模态测试时自适应方法已取得显著进展,但由于缺乏对类别条件分布(class-conditional distributions)的显式建模,具备准确预测与可靠决策边界仍存在问题。
经典的高斯判别分析(Gaussian Discriminant Analysis, GDA)提供了一种简洁的类别条件分布建模方式,并在单模态任务中取得了一定程度的性能提升。然而,在多模态测试时自适应场景下,由于模态间普遍存在固有的分布不对称性,直接应用经典GDA进行类别条件建模往往效果受限。
为此,研究团队提出了一种面向多模态测试时自适应的概率校准方法。该方法通过对多模态特征及单模态特征的类别条件分布进行显式高斯建模,刻画测试阶段各类别在特征空间中的统计结构;同时结合自适应对比式不对称校正机制,缓解不同模态分布偏移程度不一致所带来的表征失衡问题,从而提升预测结果的校准性与决策边界的可靠性。
研究团队在多个代表性基准数据集上进行了广泛实验。实验结果表明,与现有多模态测试时自适应基线方法相比,该方法在不同分布偏移场景下通常能够取得更好的分类效果,展现出对测试阶段分布变化具有较强适应性。
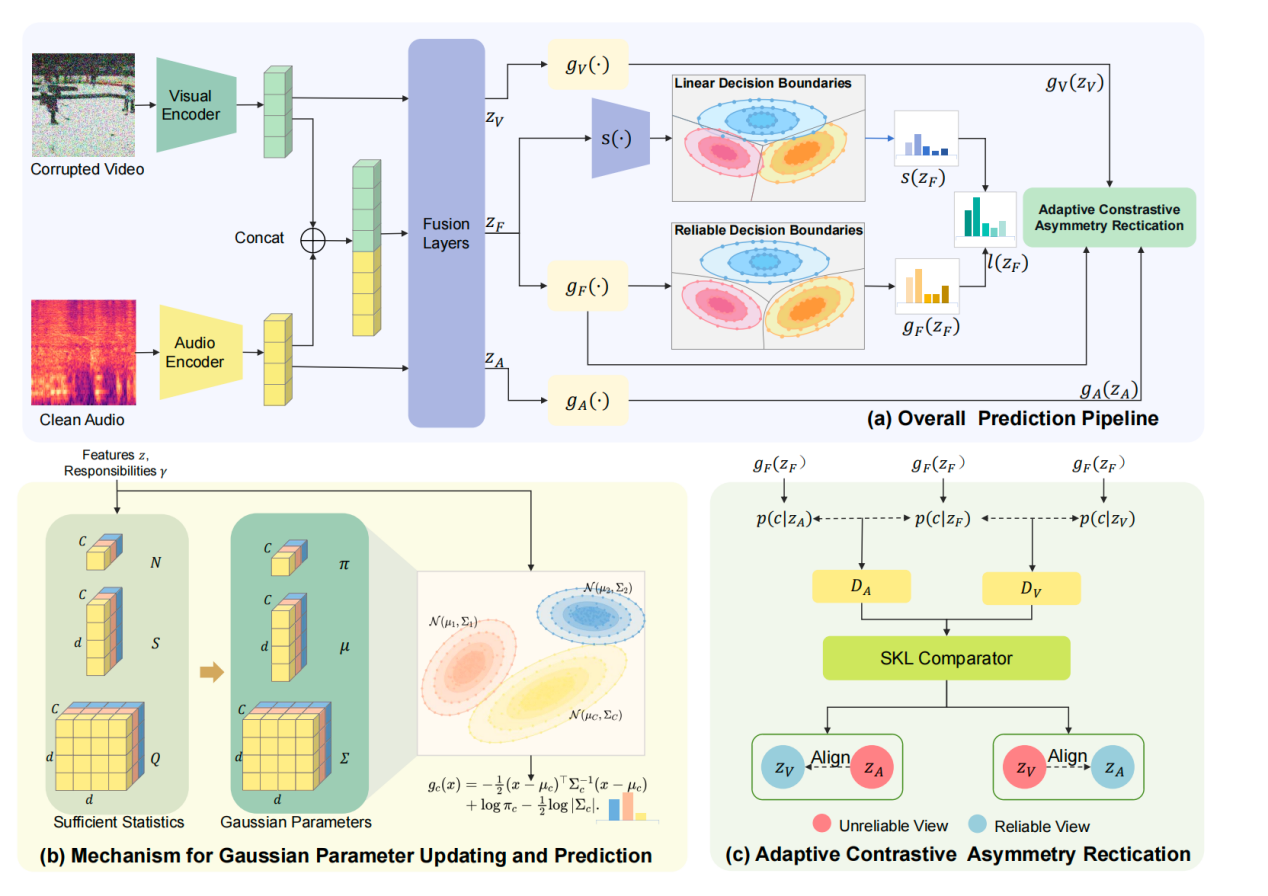
方法框架图
论文链接:https://arxiv.org/pdf/2604.19093
2. COPO: Causal-Oriented Policy Optimization for Hallucinations of MLLMs
作者:郭沛正、王婧瑶、强文文、周嘉欢、郑昌文、华刚
多模态大语言模型(MLLM)的“幻觉”现象是指模型生成的内容与视觉输入不符,跨模态对齐存在偏差。研究团队通过实证发现,MLLM相较于纯文本LLM,通常更关注与任务无关的背景区域。模型对视觉背景信息虚假关联的依赖,团队分析认为源于结果导向奖励机制的设计局限——基于结果的正确性给予奖励,一旦模型依赖无关背景信息偶然得出正确结果,这种错误推理过程仍会被固化,进而表现为偏离事实且表达流畅的“幻觉”输出。
为缓解因虚假关联引发的“幻觉”问题,研究团队提出了面向因果的策略优化方法(Causal-Oriented Policy Optimization, COPO),核心在于引入因果完整性奖励,通过量化推理生成过程中各个Token的因果充分性与因果必要性,引导模型精准聚焦具备因果支撑的关键特征。在优化阶段,COPO以组相对策略优化框架(Group Relative Policy Optimization, GRPO)为基础,将因果奖励整合至GRPO的推理Token优势函数中,实现了推理过程Token级别的因果监督。
团队在多个主流多模态大模型和标准幻觉评估基准上系统测试了COPO方法,并与现有多项基线方法进行了对比。结果表明,COPO能够抑制模型生成过程中的虚假关联,有效降低幻觉错误率,并提升输出事实的一致性。消融实验与计算开销显示,COPO的充分性与必要性约束模块不仅有效,还在性能表现与计算开销之间展现出了良好的平衡与应用价值。
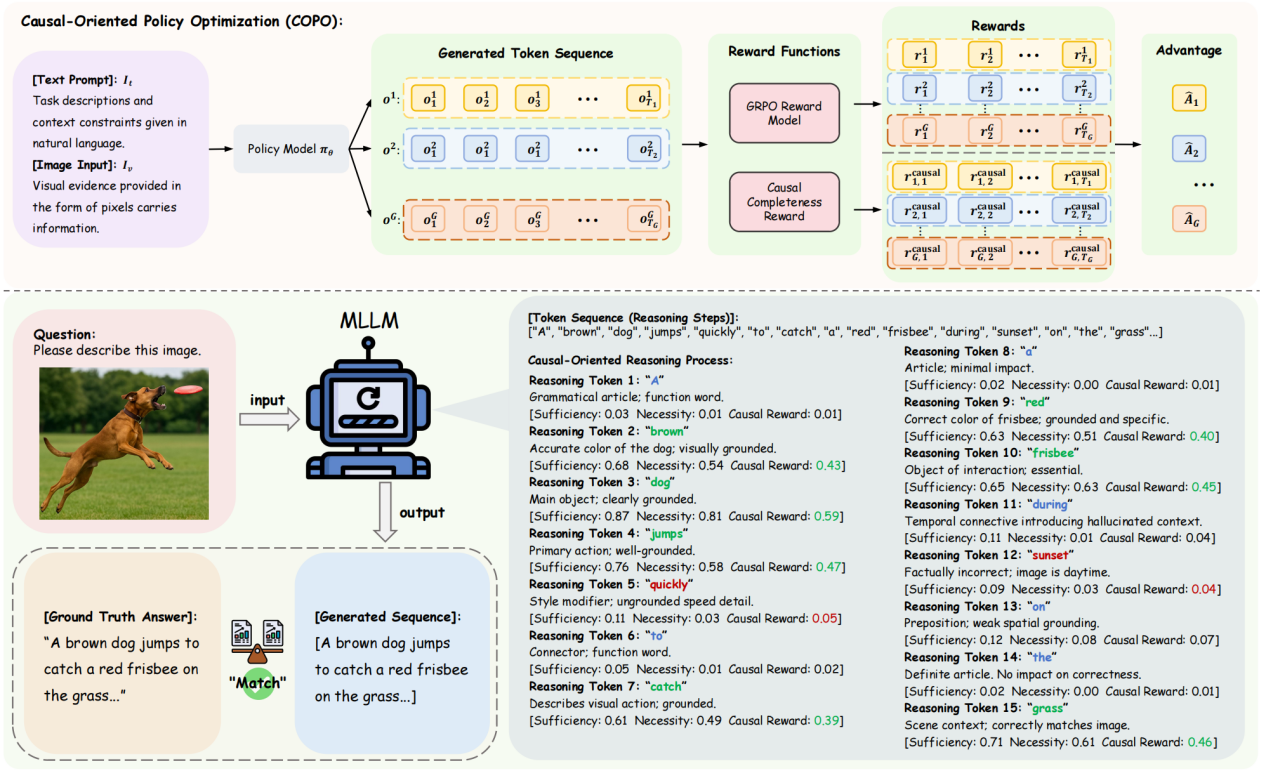
方法框架图
论文链接:https://arxiv.org/pdf/2508.04182
3. Test-Time Perturbation Learning with Delayed Feedback for Vision-Language-Action Models
作者:臧泽华、王惜、孙富春、许霄、刘立祥、周嘉欢、李江梦
视觉-语言-动作模型(Vision-Language-Action, VLA)在序列决策任务中表现优异,但面对环境细微变化(如物体姿态的微小变动)仍显脆弱。研究团队将这种脆弱性归因于轨迹过拟合,即模型过度关注伪相关线索,倾向于机械复现记忆动作。
为解决这一问题,研究团队提出一种延迟反馈扰动学习框架(Perturbation learning with Delayed Feedback, PDF)。该框架无需额外验证器,可在不微调基座模型的情况下提升决策性能。PDF主要通过基于不确定性的数据增强和动作投票缓解伪相关性,同时采用自适应调度器分配增强预算以平衡性能与效率。为进一步提升稳定性,PDF还学习了一个轻量级扰动模块,在延迟反馈信号的指导下回顾性调整动作logits,从而修正部分高置信度但错误的预测。
在基准平台LIBERO和Atari上的实验结果表明,PDF方法在任务成功率上优于强VLA基线、测试时适应方法甚至微调方法,且额外计算开销极小。其中,PDF任务成功率相较于VLA模型OpenVLA,提升了7.4%;相较于JAT基线模型,PDF的人类标准化得分提升了10.3%。
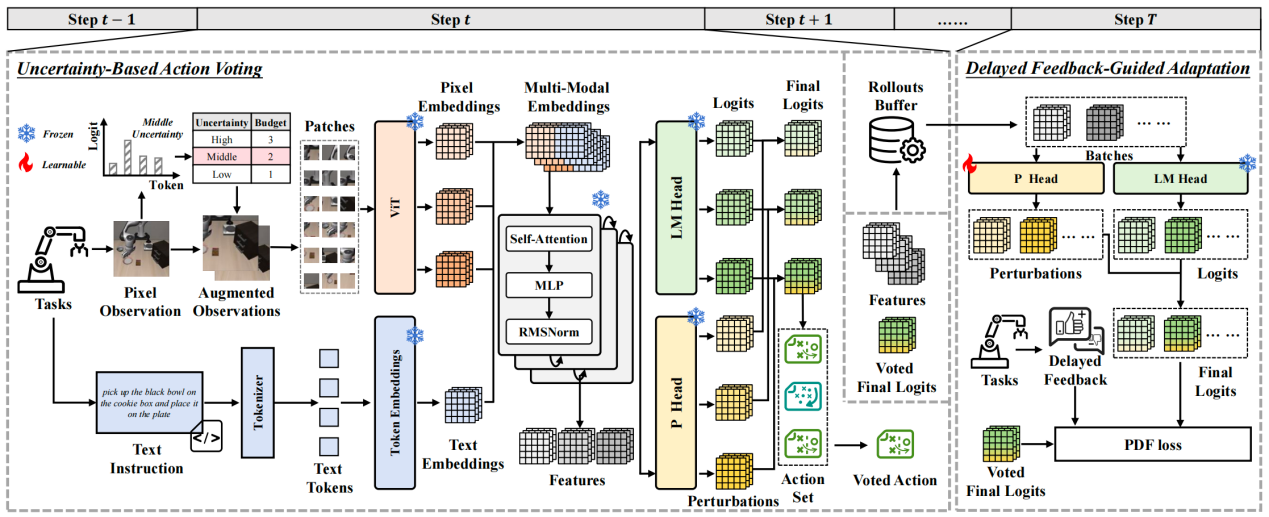
方法框架图




