
软件所提出增强图基础模型泛化性的双曲RAG框架
文章来源: | 发布时间:2026-06-18 | 【打印】 【关闭】
近日,中国科学院软件研究所研究团队提出了一种面向图基础模型的双曲检索增强生成框架。该研究从表示空间的几何特性出发,系统重构了检索增强生成(RAG)流程,以提升图基础模型在零样本场景下的泛化能力。相关成果论文Generalizing Graph Foundation Models via Hyperbolic Retrieval-Augmented Generation被数据挖掘领域顶级国际学术会议ACM SIGKDD 2026接收,第一作者博士生靳毅凡,通讯作者为李江梦副研究员。
图基础模型通过大规模预训练实现了跨域图表示学习,但其参数化知识难以应对推理阶段的数据分布变化,泛化能力受限。RAG算法通过动态引入外部知识库,提供了无需重新训练的解决思路。
然而,研究团队指出,现有基于欧氏空间的RAG方法存在几何缺陷:欧氏空间体积呈多项式增长,而外部知识库呈指数型层次扩展结构,二者不匹配。这带来两个问题:一是语义粒度丢失,粗细概念在欧氏空间中被压缩到邻近区域,难以区分;二是枢纽现象,欧氏空间的有限容量使得大量实体拥挤,部分枢纽节点反复出现在不同查询结果中,降低了检索结果的多样性和特异性。因此,提升图基础模型泛化能力,不仅要引入外部知识,还需构建在几何上适配层次化知识库的索引与检索机制。
针对上述问题,研究团队提出了HyRAG框架,在双曲空间中系统性重构RAG流程。该框架首先将外部知识库的语义特征嵌入双曲空间,通过优化使得不同粒度的概念在空间中自然分层——粗粒度概念靠近中心,细粒度概念趋于边界,从而在索引构建阶段保留知识的层次结构。在检索阶段,框架利用大语言模型将查询重构为粗粒度与细粒度两类查询,并在双曲空间中分别采用不同的检索策略:粗粒度查询侧重平衡相关性与多样性以获取全局语义锚点,细粒度查询则强调局部语义特异性。在知识融合阶段,框架从特征和结构两个层面将检索到的知识注入图基础模型,并通过门控机制动态调节对检索知识的依赖程度——当原始模型预测模糊时,更多引入外部知识进行辅助判断。
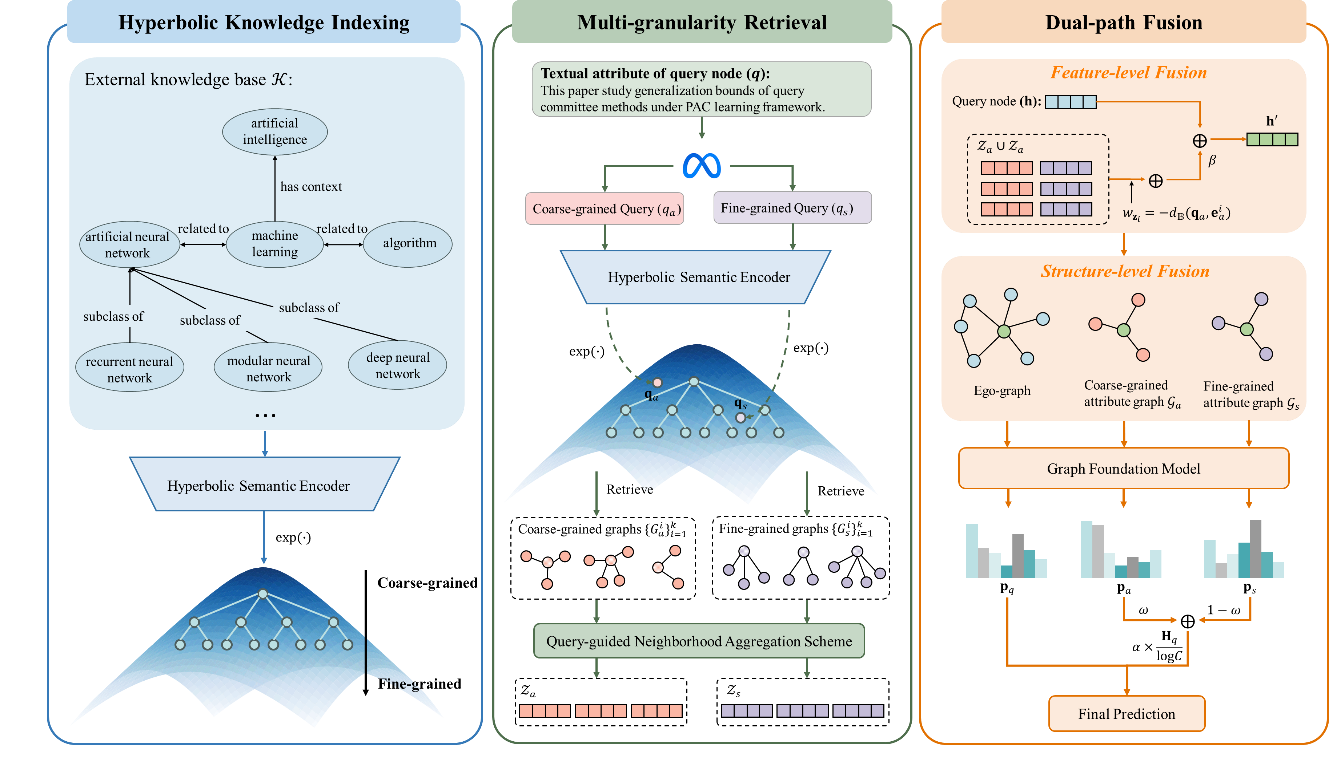
架构图
研究团队在涵盖学术、电商、社交网络等领域的7个图数据集上开展了零样本设置下的对比实验,将HyRAG与13种基线方法进行了比较。实验结果显示,在节点分类任务中,HyRAG在所有数据集上均取得最优性能。与当前最先进的图基础模型GraphCLIP相比,平均准确率提升2.16%;与同属检索增强范式的欧氏空间方法RAGRAPH相比,平均提升0.82%,配对t检验的p值为0.014,证实了性能增益具有统计显著性。消融实验表明,移除双曲索引导致性能下降最为显著,验证了双曲几何在保持层次结构方面的优势;多粒度检索与双路融合的各组件均具有不可替代的作用。
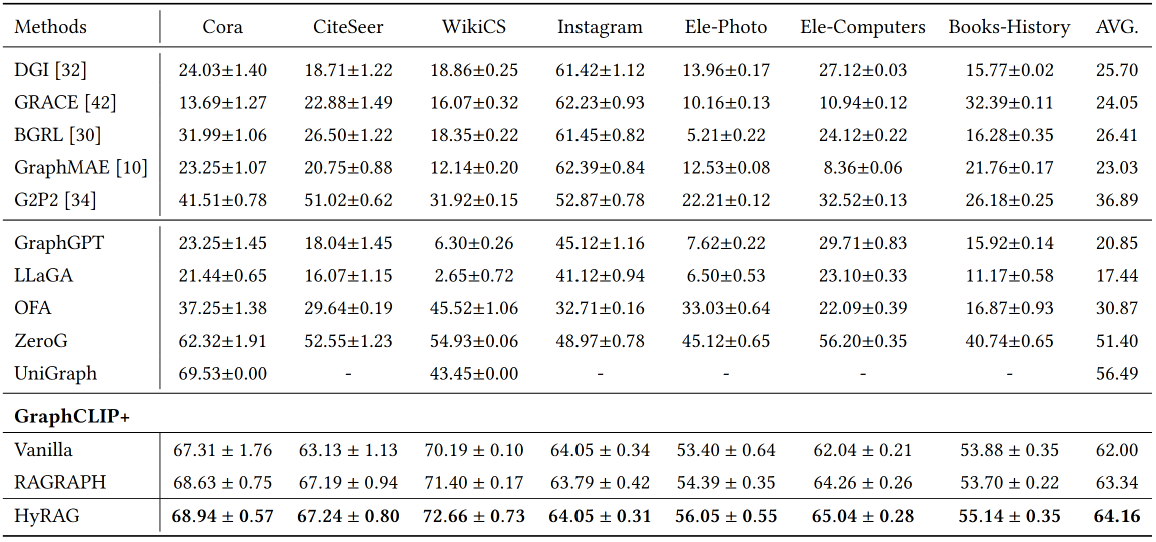
零样本节点分类任务上的准确率比较
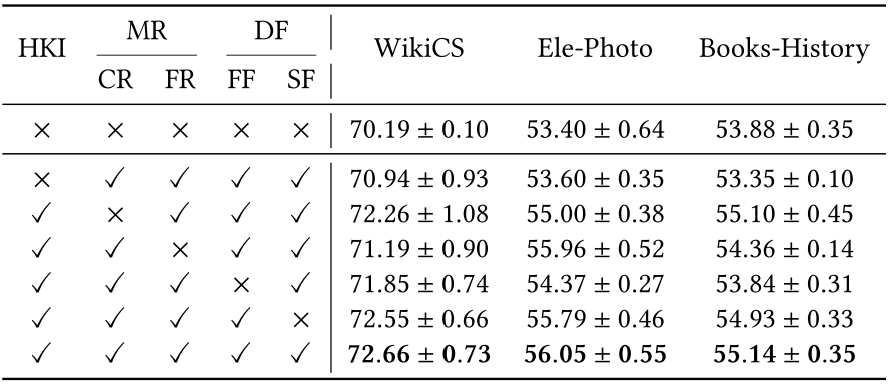
消融实验结果




